Talep tahmini, işletmelerin stoklarını ve üretimlerini optimize etmeleri, müşteri memnuniyetini artırmaları ve maliyetleri düşürmeleri için kritik öneme sahiptir. Ancak, bu görevi manuel olarak yapmak zor ve zaman alıcı olabilir.
Google Vertex AI AutoML Demand Forecasting, işletmelerin bu zorluğu otomatik olarak aşmalarına yardımcı olan bir makine öğrenimi hizmetidir. Bu hizmet, işletmelerin geçmiş satış verileri ve diğer ilgili verileri kullanarak gelecekteki talepleri tahmin etmesini sağlar.
Vertex AI AutoML Demand Forecasting’in Avantajları:
- Otomasyon: Vertex AI AutoML Demand Forecasting, işletmelerin talep tahmini sürecini tamamen otomatikleştirir. Bu iyileştirme, işletmelerin bu görevi manuel olarak yapmak için harcadıkları zaman ve kaynakları önemli ölçüde azaltır.
- Doğruluk: Vertex AI AutoML Demand Forecasting, işletmelerin stoklarını ve üretimlerini optimize etmelerine ve müşteri memnuniyetini artırmalarına olanak tanıyarak gelecekteki talepleri daha doğru bir şekilde tahmin etmelerine yardımcı olur.
- Esneklik: Vertex AI AutoML Demand Forecasting, işletmelerin kendi benzersiz ihtiyaçlarına göre talep tahmini modellerini oluşturmalarına olanak tanıyarak farklı veri türlerini ve iş gereksinimlerini destekler.
Vertex AI AutoML Demand Forecasting, geniş yelpazede birçok sektörde ve işletmede kullanılmaya uygundur. Örneğin, perakende sektöründe çalışan bir işletme, gelecekte satılacak ürün taleplerini tahmin ederek şirketin stoklarını optimize etmesine ve müşteri memnuniyetini artırmasına yardımcı olmak için bu hizmeti kullanabilir. Bunun yanı sıra, bir üretim şirketi, gelecekteki üretim ihtiyaçlarını tahmin etmek için de bu hizmeti kullanabilir ve şirketin üretim maliyetlerini düşürmesine, karlılığını artırmasına yardımcı olur.
Özetle, Vertex AI AutoML Demand Forecasting, işletmelerin talep tahmini sürecini otomatikleştirmek ve doğruluğunu artırmak için güçlü bir araçtır. Bu hizmet, işletmelerin stoklarını ve üretimlerini optimize etmelerine, müşteri memnuniyetini artırmalarına ve maliyetleri düşürmelerine yardımcı olabilir.
Vertex AI AutoML Demand Forecasting Nasıl Kullanılır?
Vertex AI AutoML Demand Forecasting’i kullanmak için aşağıdaki adımları uygulayın:
- Google Cloud Platform’da bir Vertex AI projesi oluşturun veya varolan bir projenizi seçin.
- Projede Vertex AI AutoML Demand Forecasting hizmetini etkinleştirin.
- Etkinleştirmek için bu adımları takip edin:
- Talep tahmini modelinizi oluşturmak için aşağıda detaylarını paylaştığımız şekilde bir veri kümesi sağlayın.
- Modelinizi eğitin ve değerlendirin.
- Modelinizi üretime alın.
Adımların ilerleyişini daha iyi kavrayabilmek için aşağıda görselleştirilerek detaylı bir rehber sunulmuştur.
- Dataset’i oluşturma
“Vertex AI Datasets” sekmesine giriyoruz. Burada datasetimize benzersiz bir isim veriyoruz. “Tabular” sekmesinden “Forecasting” seçip, “Region” kısmı altından lokasyonu belirliyoruz ve datasetimizi oluşturuyoruz.
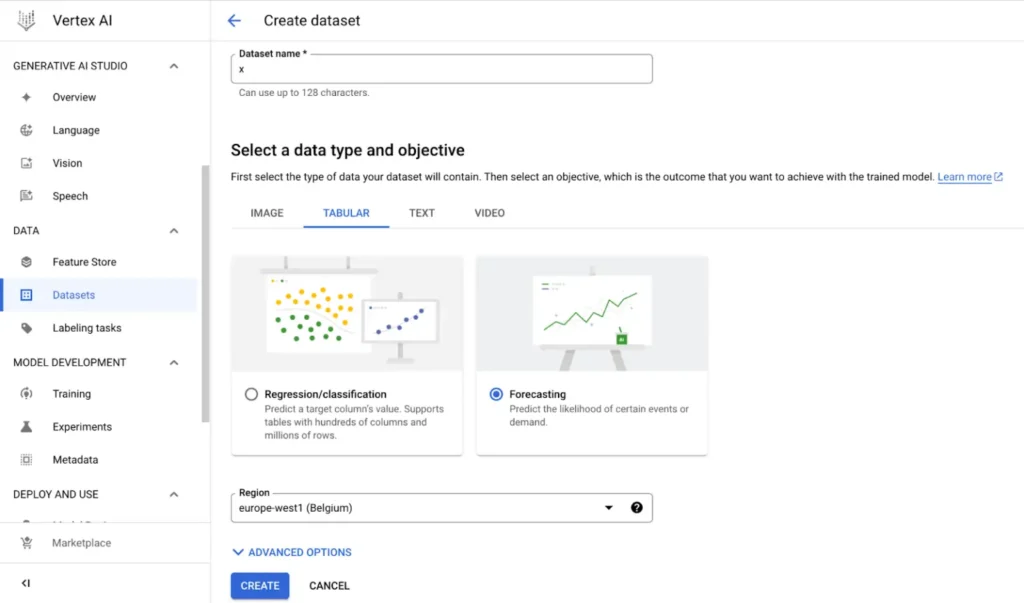
Görsel 1: Vertex AI Dataset oluşturma.
- Dataset’in Kaynağını Belirleme
“Dataset” oluşturduktan sonra datasetimizin kaynağını belirliyoruz. Burada yerel (kişisel bilgisayarınızdan) veya Cloud Storage’tan CSV dosyası ya da BigQuery’den tablo veya view yükleyebilirsiniz.
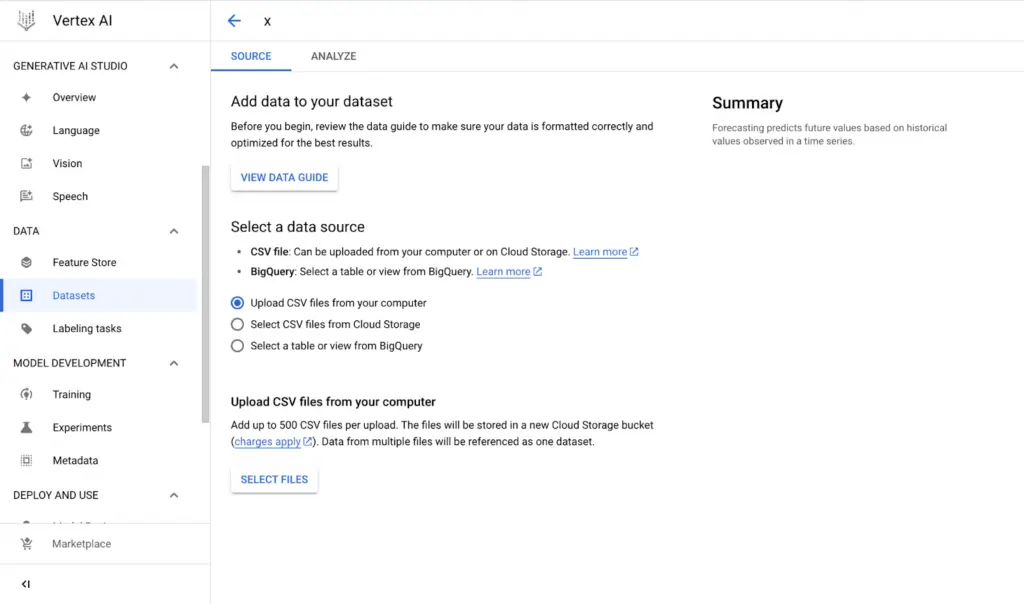
Görsel 2: Datasets için source (kaynak) seçme.
- Training için Model Belirleme ve Eğitme
Oluşturulan datasetimiz üzerinden “Train new model” seçeneğini seçerek yeni model eğitimi yapabiliriz. Açılan pencerede datasetimize uygun eğitim yöntemi seçiyoruz.
- Time series Dense Encoder (TiDE): Optimize edilmiş DNN based encoder-decoder modelidir. Özellikle uzun “context”ler ve “horizon”lar için hızlı eğitim ve sonuçlarla iyi model kalitesi sunar.
- Temporal Fusion Transformer(TFT): Attention-based DNN modeli, multi-horizon forecasting ile modelin yüksek doğrulukta ve yorumlanabilirlikte olmasını sağlamak üzere tasarlanmıştır.
- AutoML(Default): Çok çeşitli kullanım senaryolarında iyi performans gösterir. Daha uzun eğitim süresine sahiptir.
- Seq2Seq+: Deney yapmak için iyi bir seçimdir. Algoritmanın AutoML’den daha hızlı yakınlaşmaya ulaşması muhtemeldir çünkü mimarisi daha basittir ve daha küçük bir arama alanı kullanır. Yapılan denemelerde, Seq2Seq+’nın düşük bütçe kullanarak ve boyutu 1 GB’tan küçük veri kümelerinde iyi performans gösterdiğini ortaya koymaktadır.
- Custom Training: Vertex AI, TensorFlow, scikit-learn, XGBoost ve PyTorch gibi popüler ML kodlama çerçeveleriyle entegredir. Sahip olduğunuz kendi modellerinizi eğitebilirsiniz.
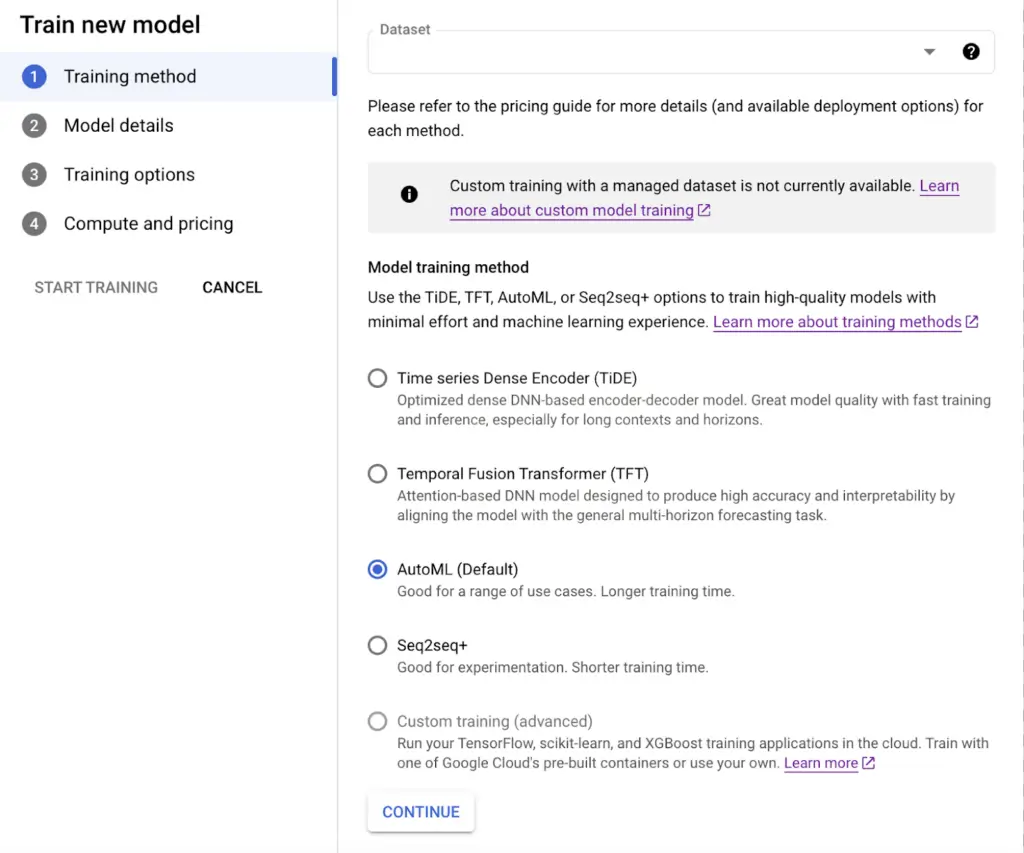
Görsel 3: Model Training ve Methodları
- Seçilen Modelin Detaylarını Belirleme
İhtiyaçlarımıza ve yeteneklerimize göre modelimizi belirledikten sonraki adımda modeli tekrardan ihtiyaçlarımız doğrultusunda şekillendirmek kalıyor. Bunun için sonraki pencerede karşımıza çıkan adımlar şu şekilde açıklanabilir:
- “Target column” seçimini yapıyoruz. Burada dataset içerisinde tahmin edilmesini istediğimiz kolonu belirtiyoruz.
- “Series Identifier column” seçimini yapıyoruz. Seçilen kolon her satırda olması gerekmektedir. Birden fazla “series identifier column” seçilmesi model performansınızı arttıracaktır.
- “Timestamp column” seçimini yapıyoruz. Bu kolon gözlemin yapıldığı zaman aralığını temsil eder. Seçilen kolon her satırda olması gerekmektedir.
- “Data granularity”, veri setindeki satırlar arasındaki zaman aralığını belirtmek için kullanılır. Dakika bazlı ya da saatlik, günlük, haftalık, aylık veya yıllık olarak ayarlanabilir. Ayrıca burada seçilen değer “forecast horizon” ve “context window” için birim olacaktır.
- “Data granularity” daily temel olarak seçildiğinde “Holiday” seçeneği aktifleşir, dataset için uygun olan bölge seçilerek o bölgeye tanımlanmış tatiller model için kullanılabilir.
- “Context window”, modelin geçmiş verileri kullanarak tahmin oluşturmak için kullanacağı veri miktarını belirtir. Bu, modelin öğrenebileceği kalıpların sayısını belirler. “Context window” ne kadar uzun olursa, model o kadar fazla kalıp öğrenebilir ve daha doğru tahminler oluşturabilir. Ancak, “context window” çok uzun olursa, modelin öğrenmesi ve tahmin oluşturması daha uzun sürebilir.
- “Forecast horizon” ise modelin tahmin oluşturacağı süreyi belirtir. Bu, modelin tahminlerinin ne kadar uzun süreli olacağını belirler. “Forecast horizon” ne kadar uzun olursa, modelin tahminleri o kadar uzun süreli olabilir. Ancak, “forecast horizon” çok uzun olursa, modelin tahminleri belirsiz hale gelebilir
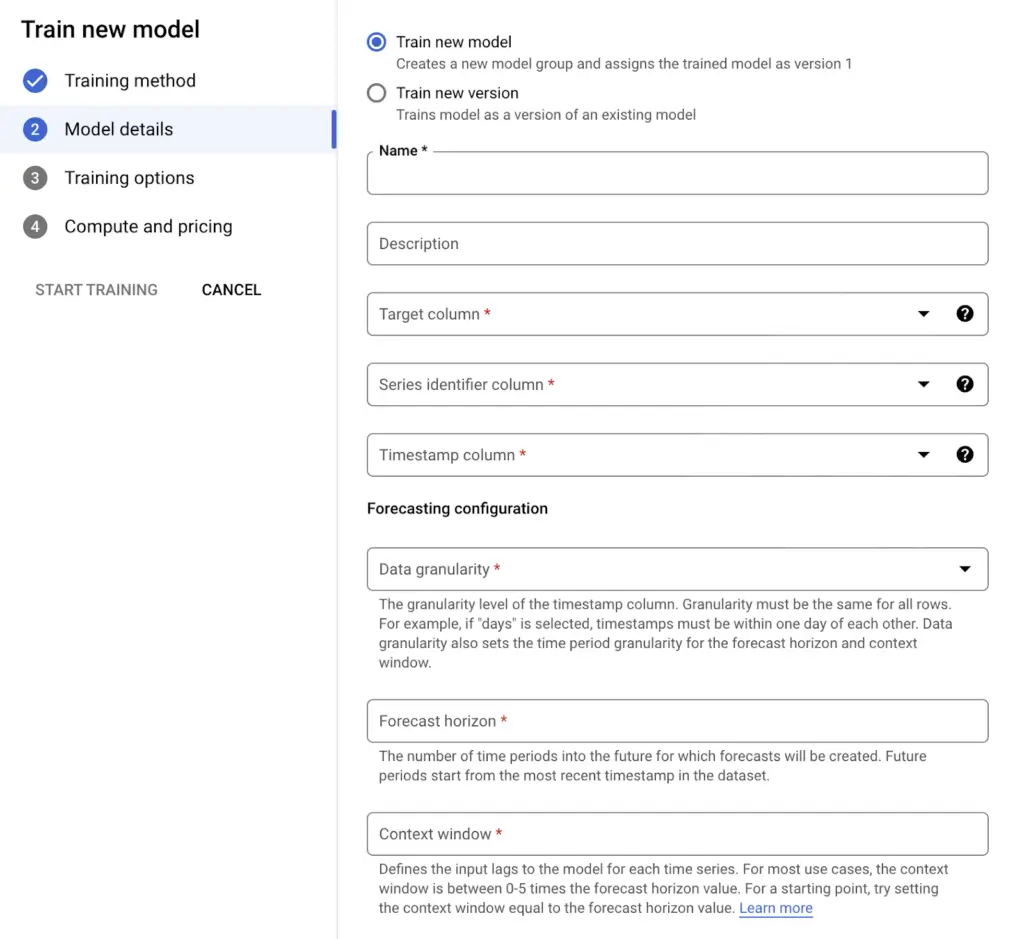
Görsel 4: Model Training Details
5. Model’in Data’sının Ayrılıp Anlamlandırılması
ML modelleri eğitilirken data Training, Validation ve Testing olmak üzere genellikle üç parçaya ayrılır. Büyük yüzdeyi oluşturan training modelin eğitilmesinde kullanılacak data’dır. Eğitimi tamamlanan model daha önce hiç görmediği datasetler üzerinde ne kadar iyi tahminler yapacağını görmek için ise Testing ve Validation dataları kullanılır. Buradaki sonuçlara göre modelin performansı yorumlanır ve gerekirse iyileştirmeler yapılır. AutoML bizim için bunu otomatik yapar. Arayüzün detayları ve kullanımı şu şekilde açıklanabilir.
- Model başarımını kontrol edebilmek için “Export test dataset to BigQuery” seçeneğini işaretleyerek belirlediğiniz hedef tabloya test verisini gönderebilirsiniz.
- Data split kısmında bahsedilen data ayrıştırması yapılabilir. Varsayılan ayarında verinin ilk %80’i Training (Eğitim), sonraki %10’u Validation (Doğrulama), sonraki %10’u da Test için kullanır. Eğer istenirse veriye bir kolon eklenerek hangi kolonun test, doğrulama ya da eğitim için kullanılacağı belirlenebilir.
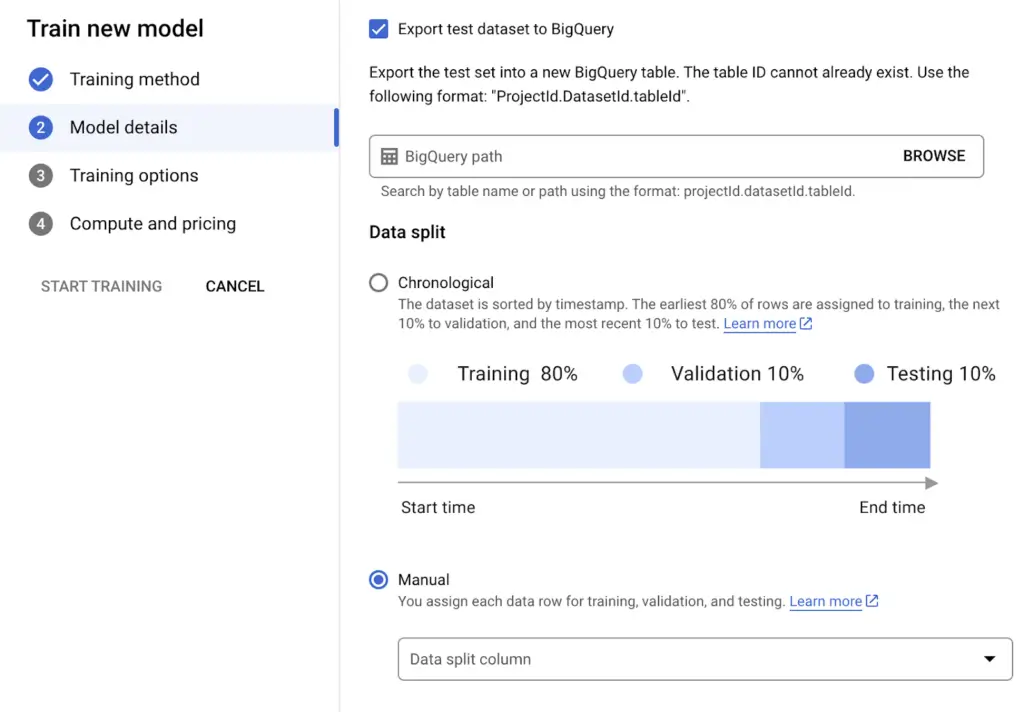
Görsel 5: Model’in dataset’ini anlamlı kullanım için ayırma.
6. Rolling Window Stratejisi Ayarı
Data’nızı anlamlı şekilde ayırdıktan sonraki adım ise biraz daha detaylı olacak biçimde “rolling window strategies” ayarını yapmaktır. Bu ayarı daha detaylı biçimde anlatmak gerekirse:
Tahmin için kullanılan veri seti, zaman içinde kaydırmalı bir pencere kullanılarak oluşturulur. Pencerenin boyutu “context window” olarak adlandırılır. “Rolling window strategies” zaman serisi verilerinde trendler ve sezonsallık gibi kalıpları yakalamak için etkili bir yöntemdir. Bu kalıpları yakalayarak, daha doğru tahminler elde edilebilir.
Varsayılan olarak “max count” seçili biçimde gelir. “Data granularity” kısmında seçilen birim üzerinden maksimum pencere hedeflenir. Sezonsal ya da haftalık gibi seçenekler için “Stride length”, varsayılan olarak kolon ekleyerek strateji belirlenmek istenirse de “column” seçeneğini seçerek konfigürasyon sağlanabilir.
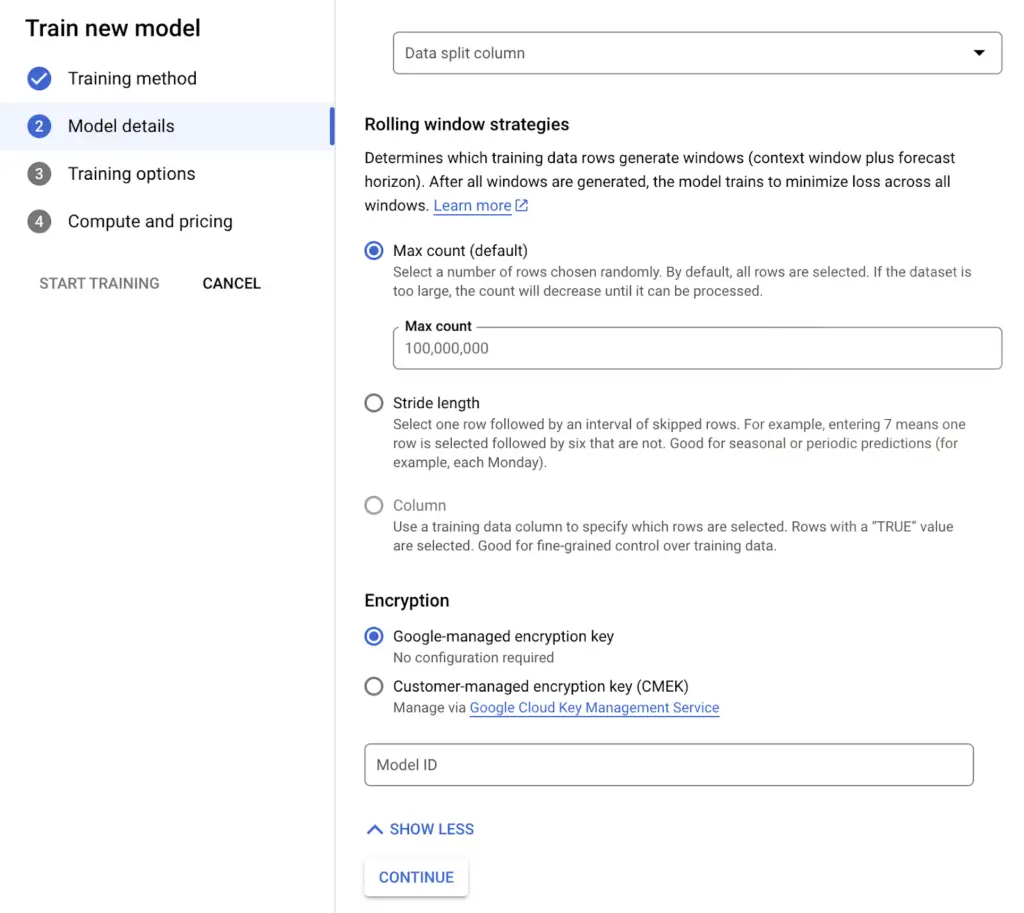
Görsel 6: Rolling Window Stratejisi Belirleme
7. Tahminleme için Kolonların Anlamlandırılması
Model detaylarını belirledikten sonra elimizdeki modelde var olan dataların ayrıldığı her bir kolonu düzenleyip daha iyi tahminler yapmak için “Training options” bölümünde kolon bazlı detayları girerek devam ederiz.
- “Transformation” varsayılan olarak seçilidir, değiştirilmek istenirse “numeric” ya da “categorical” seçilebilir.
- “Feature type” olarak “covariate” veya “attribute” seçilebilir.
- Attribute: zamanla değişmeyen statik niteliklerdir. Bu kolonlar ürünle alakalı bilgi taşır. Satılan ürünün, boyutu, rengi gibi özellikler “attribute” olarak ele alınır.
- Covariate: zamanla değişmesi beklenen dışsal bir değişkendir. Bir kolon “covariate” olarak işaretlenirse “forecast horizon”da her nokta için bu değişkenin sağlanması gerekmektedir. Tatiller, planlanmış etkinlikler “covariate” olarak ele alınır.
- Son olarak da “available at forecast” durumu belirlenir.
- “Forecast” zamanında modele sağlanabilecek kolonları “available”, modele sağlayamayacağımız kolonları da “not available” olarak işaretleriz. Örnek olarak, hava durumu bilgisini içeren bir kolon “not available” olarak işaretlenir.
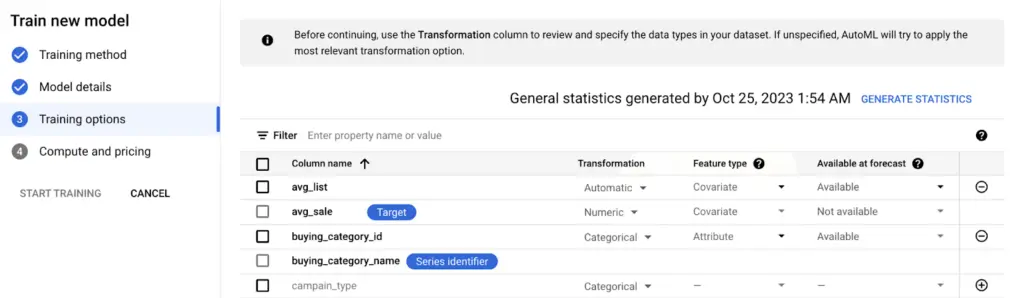
Görsel 7: Tahminleme için Kolon Ayarı
- Kolon Önceliklendirilmesi ve Optimizasyon Objektif Seçimi
Kolonların model için anlamlandırılmasının ardından hangi satırların bizim için daha önemli olduğunu niteleyebilmek için “weight column” özelliğini kullanabiliriz. Varsayılan ayarlarında model tarafından her kolonun ağırlığı eşit olarak ele alınır fakat bizim modelde daha ağır basmasını istediğimiz, öne çıkarılmasını istediğimiz satırlar var ise bu satırlar için bir “weight” kolonu oluşturulup bu satırların modele olan etkisini arttırabiliriz.
Önemli kolonlar belirlendikten sonra modelimiz için optimizasyon objektifi seçilir:
- RMSE: Root-Mean-Squared Error’u minimize etmektedir. Daha uçlarda kalan durumları daha iyi yakalar ve tahminler sırasında daha az önyargılı davranır. Varsayılan olarak seçilidir.
- MAE: Mean-Absolute Error’u minimize etmektedir. Daha uçlarda kalan durumların, model üzerindeki etkisini daha az görüp model için aykırı değerler olarak ele alır.
- RMSLE: Root-Mean-Squared Log Error’u minimize etmektedir. Hatayı mutlak değere göre hatanın boyutuna göre cezalandırma gerçekleştirir. Hem tahmin edilen hem de gerçek değerlerin büyük olduğu durumlarda kullanışlıdır.
- RMSPE: Root-Mean-Squared Percentage Error’u minimize etmektedir. RMSE’ye benzerdir. Daha geniş bir değer aralığını daha doğru tahmin eder.
- WAPE: Weighted Absolute Percentage Error (WAPE) ve Mean-Absolute Error kombinasyonunu minimize etmek için kullanılır. Gerçek değerler düşük olduğunda kullanışlıdır.
- Quantile Loss: Tahminlerdeki belirsizliği ölçmek için kullanılır. Bir tahminin belirli bir aralıkta olma olasılığını ölçer.
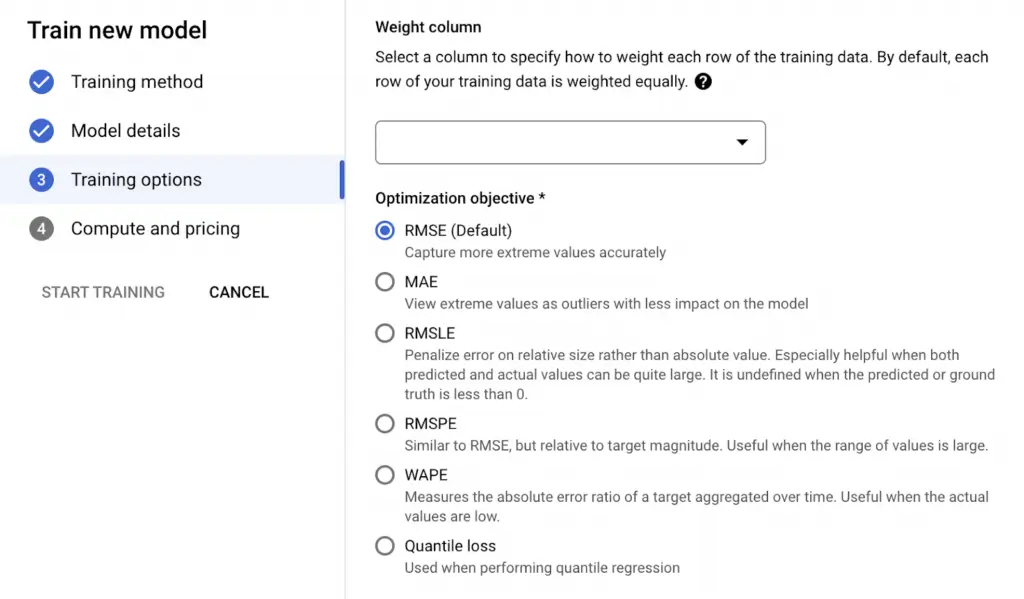
Görsel 8: Weight Column ve Optimization Objective (Optimizasyon Objektifi) Seçimi
- Hiyerarşik Tahminleme Ayarları
Time series genellikle iç içe geçmiş bir hiyerarşide yapılandırılır. Örneğin, bir perakendecinin sattığı ürün envanterinin tamamı ürün kategorilerine ayrılabilir. Kategoriler ayrıca bireysel ürünlere ayrılabilir. Gelecekteki satışları tahmin ederken, bir kategorinin ürünlerine ilişkin tahminler, kategorinin kendisine ilişkin tahminlere eklenmeli ve hiyerarşiyi yükseltmelidir. Benzer şekilde tek bir time series’in zaman boyutu da bir hiyerarşi sergileyebilir. Örneğin, tek bir ürün için gün düzeyinde tahmini satışların, ürünün tahmini haftalık satışlarına eklenmesi gerekir.
Vertex AI’da hiyerarşik tahmin, toplu tahminler için ek kayıp terimlerini dahil ederek zaman serisinin hiyerarşik yapısını hesaba katar. Örneğin hiyerarşik grup “kategori” ise “kategori” düzeyindeki tahminler, kategorideki tüm “ürünler” için yapılan tahminlerin toplamıdır. Modelin amacı ortalama mutlak hata (MAE) ise, kayıp hem “ürün” hem de “kategori” seviyelerindeki tahminler için MAE’yi içerecektir. Bu, hiyerarşinin farklı seviyelerindeki tahminlerin tutarlılığının iyileştirilmesine yardımcı olur ve bazı durumlarda en düşük seviyedeki metrikleri bile iyileştirebilir.
Hiyerarşik tahminleme seçildiğinde karşımıza üç seçenek çıkar:
- No Grouping: herhangi bir gruplandırma yapılmadan hiyerarşik tahminleme yapılır.
- Group by columns: Seçilen kolonlar üzerinden hiyerarşik tahminleme yapılır.
- Group All : Tüm Time Series tek bir grup olarak ele alınarak hiyerarşik tahminleme yapılır.
Group by columns ya da group all seçeneklerini seçtiğimizde aşağıdaki konfigürasyonlar açılır:
- Group_columns: Training input tablonuzdaki hiyerarşi düzeyine yönelik gruplamayı tanımlayan sütun adlarıdır. Sütun veya sütunlar “time_series_attribute_columns” olmalıdır. Grup sütunu ayarlanmazsa tüm zaman serileri aynı grubun parçası olarak ele alınır ve tüm zaman serileri üzerinden toplanır.
- Group_total_weight: Grubun ağırlığı, individual loss bazında toplam zarardır. 0,0’a ayarlandıysa veya hiç ayarlanmıyorsa devre dışı kalarak modele eklenmez.
- Temporal_total_weight: Zamanın aggregated loss bazında individual loss karşısında ağırlığıdır. 0,0’a ayarlandıysa veya hiç ayarlanmıyorsa devre dışı kalarak modele eklenmez.
- Group_temporal_total_weight: Individual loss bazında toplam kaybın (grup x zaman) ağırlığı. 0,0’a ayarlandıysa veya hiç ayarlanmıyorsa devre dışı kalarak modele eklenmez. Grup sütunu ayarlanmazsa tüm zaman serileri aynı grubun parçası olarak ele alınır ve tüm zaman serileri üzerinden toplanır.
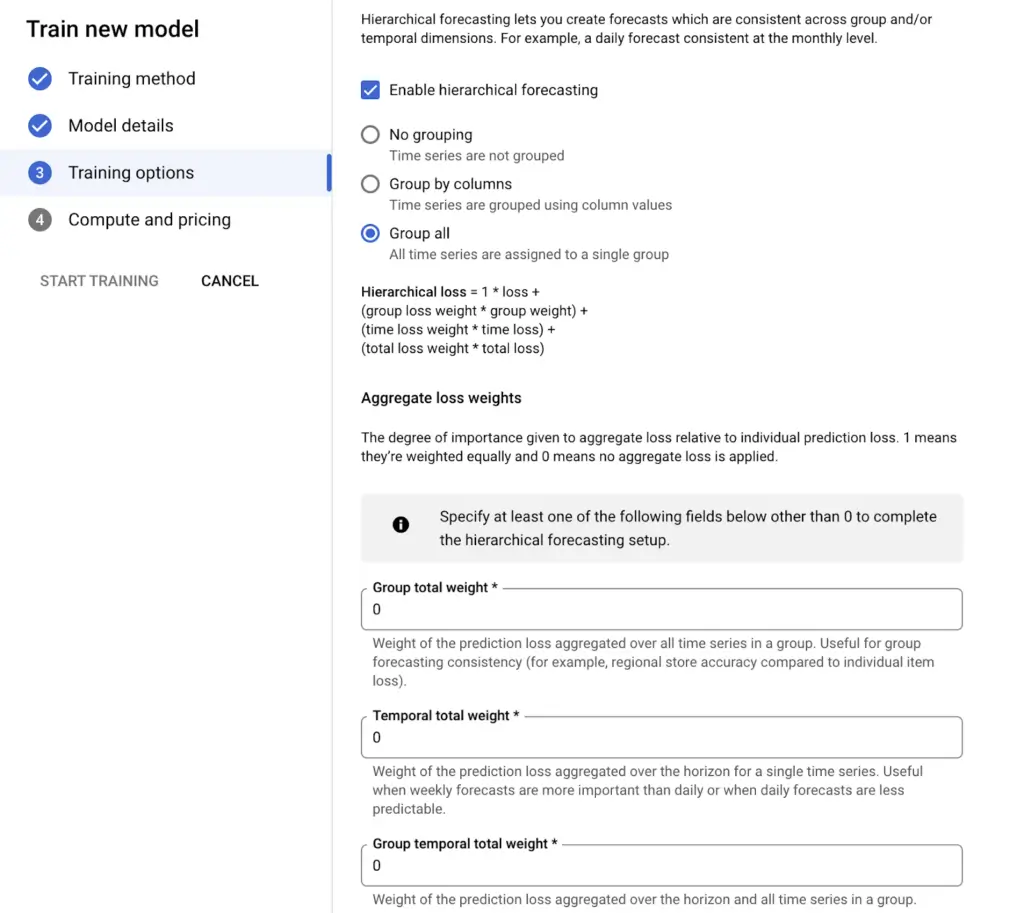
Görsel 9: Hiyerarşik Tahminleme Ayarları
10. Modeli Çalıştırma ve Bütçe Ayarı
Tüm konfigürasyonlar tamamlandıktan sonra saat çalışma üzerinden budget (bütçe) ayarlaması yapılır. 100.000 satırda 1 ila 3 saat, 1.000.000 satıra kadar 3 ila 6 saat, 10.000.000 satıra kadar 12 saat ve sonrasında satır sayısı arttıkça her 10 katta bir bütçe iki katına çıkartılarak eğitim süresi ve ücreti ayarlanabilir.
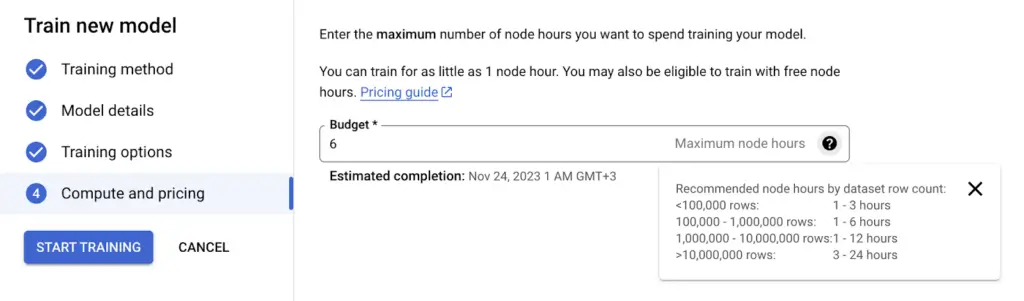
Görsel 10: Budget (Bütçe) Ayarı
Sonuç ve Öneriler
Adımları takip ettikten sonra artık işletmenizde rahatlıkla kullanabileceğiniz bir yapay zeka modeline sahipsiniz. İlerleyen süreçte modelinizi daha da iyileştirmek için birkaç öneri:
- İlk training iterasyonu için contex window ve forecast horizonu aynı değere ayarlayın ve eğitim bütçenizi en az 6 saate ayarlayın.
- Modeli aynı eğitim bütçesiyle yeniden eğitin, ancak contex windowun boyutunu forecast horizonunun 2 katına kadar iki katına çıkarın.
- İkinci modele ilişkin değerlendirme metrikleri(evaluation metrics) önemli bir iyileşme gösteriyorsa context windowu forecast horizon boyutunun 5 katına çıkararak modeli yeniden eğitin. Eğitim bütçesinde orantılı bir artış yapmayı değerlendirebilirsiniz.(ilk adımda 10 saat eğitim yaptıysanız eğitim bütçesini 50 saate çıkarın).
- İyileştirilmiş değerlendirme metriklerini(evaluation metrics) artık görmeyene veya sonuçlardan memnun kalana kadar context windowu artırmaya devam edin. İstediğiniz sonuçları üreten context windowu bulduğunuzda en düşük değerine geri dönebilirsiniz.
Yapılanları özetlemek gerekirse, varolan işletmelerimiz ve süreçlerimiz için yeterli donanıma sahip değilsek bile Vertex AI AutoML kullanarak süreçlerimize rahatlıkla yapay zeka çözümlerini dahil edebiliriz. Bu sayede, çok daha optimize ve başarılı bir şekilde ilerleyen otomatikleştirilmiş süreçler elde edilebilir. Umuyoruz, rehber niteliğinde yazılan bu yazı, adımları takip ederek süreçlerinize yapay zeka dahil etme konusunda yardımcı olur.