
Demand forecasting is critical for businesses to optimize their inventory and production, increase customer satisfaction and reduce costs. However, doing this task manually can be difficult and time-consuming.
Google Vertex AI AutoML Demand Forecasting is a machine learning service that helps businesses meet this challenge automatically. This service enables businesses to forecast future demand using historical sales data and other relevant data.
Advantages of Vertex AI AutoML Demand Forecasting:
- Automation Vertex AI AutoML Demand Forecasting fully automates the demand forecasting process for businesses. This improvement significantly reduces the time and resources businesses spend on doing this task manually.
- Accuracy Vertex AI AutoML Demand Forecasting helps businesses more accurately predict future demand, allowing them to optimize their inventory and production and improve customer satisfaction.
- Flexibility: Vertex AI AutoML Demand Forecasting supports different data types and business requirements, allowing businesses to build demand forecasting models based on their unique needs.
Vertex AI AutoML Demand Forecasting is suitable for use in a wide range of industries and businesses. For example, a retail business can use this service to forecast future demand for products to be sold, helping the company to optimize inventories and improve customer satisfaction. A manufacturing company can also use this service to forecast future production needs, helping the company to reduce production costs and increase profitability.
In summary, Vertex AI AutoML Demand Forecasting is a powerful tool for businesses to automate the demand forecasting process and improve its accuracy. This service can help businesses optimize their inventory and production, increase customer satisfaction and reduce costs.
How to Use Vertex AI AutoML Demand Forecasting
To use Vertex AI AutoML Demand Forecasting, follow the steps below:
- Create a Vertex AI project on Google Cloud Platform or select an existing project.
- Enable the Vertex AI AutoML Demand Forecasting service in the project.
- Follow these steps to activate it:
- To build your demand forecasting model, provide a dataset as detailed below.
- Train and evaluate your model.
- Put your model into production.
In order to better understand the progression of the steps, a visualized and detailed guide is presented below.
- Creating the Dataset
We enter the “Vertex AI Datasets” tab. Here we give our dataset a unique name. From the “Tabular” tab, select “Forecasting”, determine the location under the “Region” section and create our dataset.
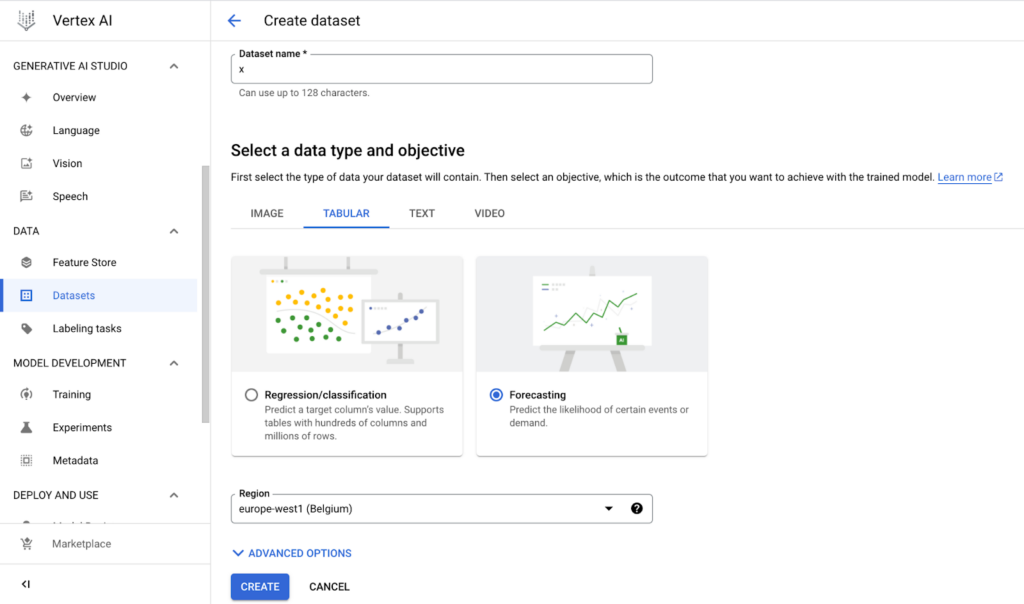
Image 1: Vertex AI Dataset creation.
- Identifying the Source of the Dataset
After creating a “dataset”, we determine the source of our dataset. Here you can upload a CSV file from local (from your personal computer) or Cloud Storage, or a table or view from BigQuery.
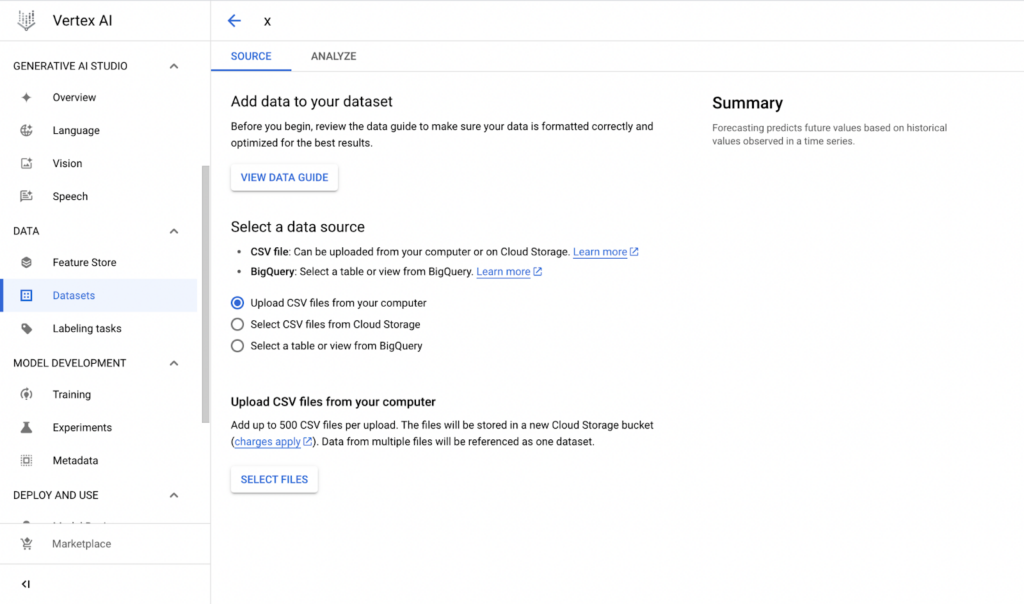
Image 2: Selecting source for datasets.
- Model Identification and Training for Training
We can train a new model by selecting the “Train new model” option on our created dataset. In the window that opens, we select the training method suitable for our dataset.
- Time series Dense Encoder (TiDE): An optimized DNN based encoder-decoder model. It offers good model quality with fast training and results, especially for long “contexts” and “horizons”.
- Temporal Fusion Transformer (TFT): Attention-based DNN model is designed to provide multi-horizon forecasting and high accuracy and interpretability of the model.
- AutoML(Default): Performs well in a wide range of usage scenarios. It has a longer training time.
- Seq2Seq+: A good choice for experimentation. The algorithm is likely to achieve faster convergence than AutoML because its architecture is simpler and it uses a smaller search space. Experiments show that Seq2Seq+ performs well using a low budget and on datasets smaller than 1 GB in size.
- Custom Training: Vertex AI is integrated with popular ML coding frameworks such as TensorFlow, scikit-learn, XGBoost and PyTorch. You can train your own models that you own.
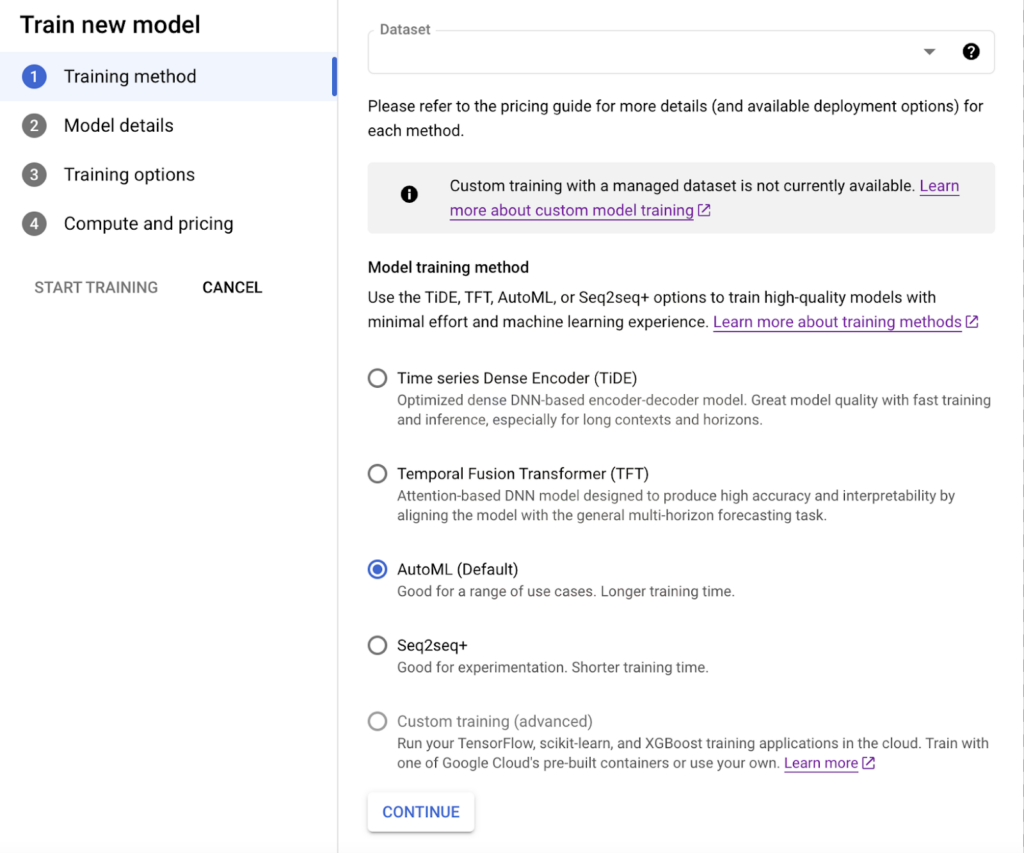
Image 3: Model Training and Methods
- Determining the Details of the Selected Model
After determining our model according to our needs and capabilities, the next step is to reshape the model according to our needs. For this, the steps that appear in the next window can be explained as follows:
- We select “Target column”. Here we specify the column we want to predict in the dataset.
- We select “Series Identifier column” . The selected column must be in each row. Selecting more than one “series identifier column” will increase your model performance.
- We select the “Timestamp column”. This column represents the time interval when the observation was made. The selected column must be in each row.
- “Data granularity” is used to specify the time interval between rows in the data set. It can be set in minutes or hourly, daily, weekly, monthly or yearly. Also the value selected here will be the unit for “forecast horizon” and “context window”.
- When “Data granularity” is selected as daily basic, the “Holiday” option is activated, the region suitable for the dataset is selected and the holidays defined for that region can be used for the model.
- The “context window” specifies the amount of data the model will use to generate predictions using historical data. This determines the number of patterns the model can learn. The longer the “context window”, the more patterns the model can learn and the more accurate predictions it can generate. However, if the “context window” is too long, the model may take longer to learn and generate predictions.
- “Forecast horizon” is the length of time the model will generate forecasts. This determines how long the model’s forecasts will be. The longer the “forecast horizon”, the longer the model’s forecasts can be. However, if the “forecast horizon” is too long, the model’s forecasts can become uncertain
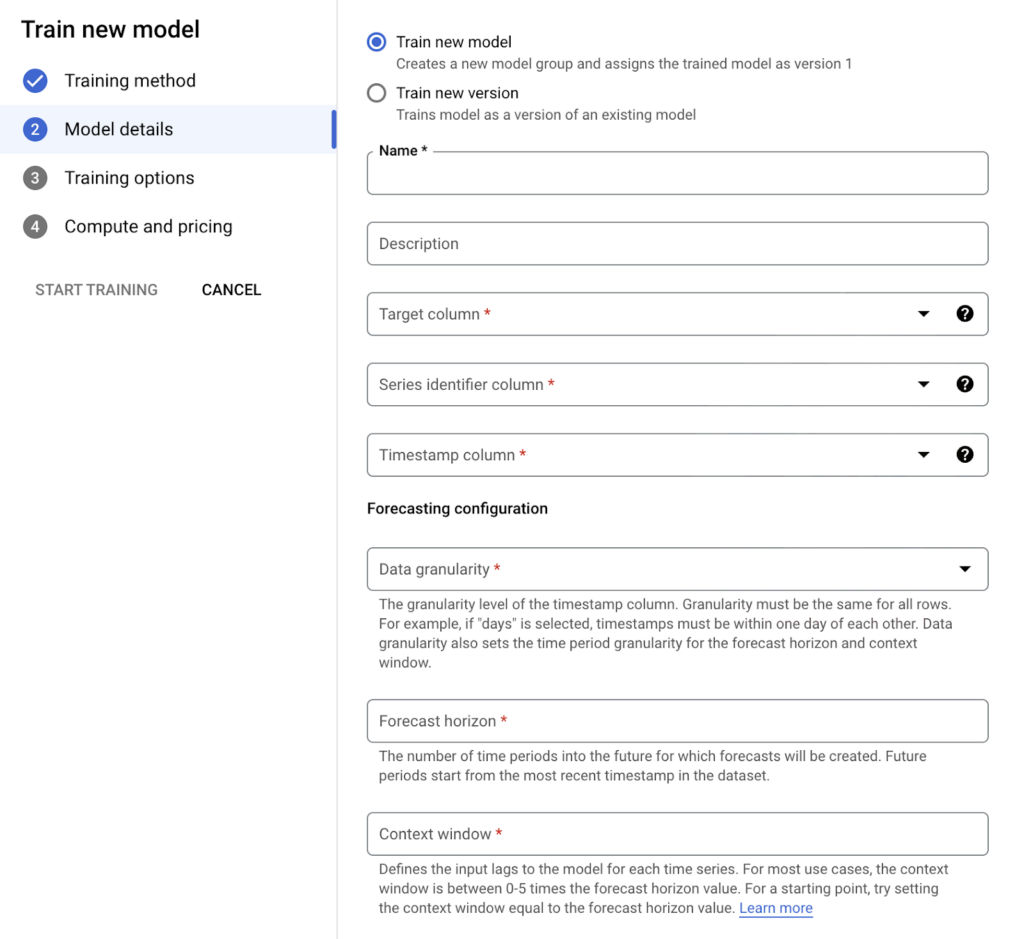
Image 4: Model Training Details
5. Separating and Making Sense of the Model’s Data
When training ML models, data is usually divided into three parts: Training, Validation and Testing. Training, which constitutes a large percentage, is the data that will be used to train the model. Testing and Validation data are used to see how well the trained model will make predictions on datasets it has never seen before. According to the results here, the performance of the model is interpreted and improvements are made if necessary. AutoML does this automatically for us. The details and usage of the interface can be explained as follows.
- In order to check the model performance, you can check the “Export test dataset to BigQuery” option and send the test data to the target table you specify.
- The data separation mentioned in the Data split section can be done. By default, the first 80% of the data is used for Training , the next 10% for Validation and the next 10% for Testing . If desired, a column can be added to the data to determine which column will be used for testing, validation or training.
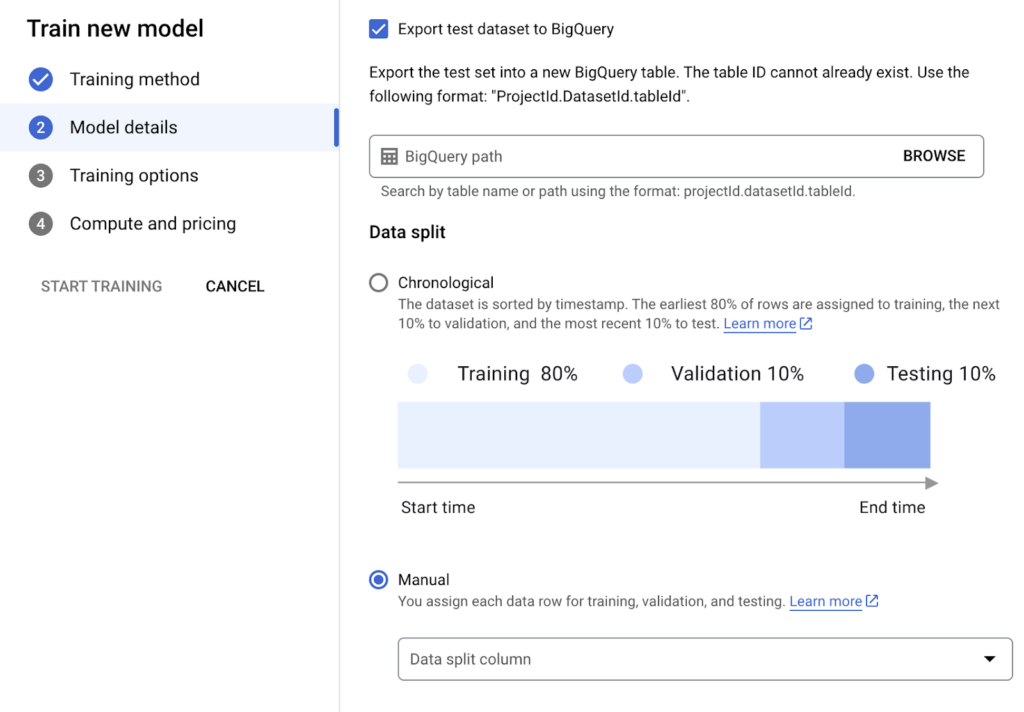
Image 5: Separating the Model’s dataset for meaningful use.
6. Rolling Window Strategy Setting
The next step after separating your data in a meaningful way is to set “rolling window strategies” in a little more detail. To explain this setting in more detail:
The dataset used for forecasting is created using a window shifted in time. The size of the window is called the “context window”. ” Rolling window strategies are an effective way to capture patterns in time series data, such as trends and seasonality. By capturing these patterns, more accurate forecasts can be obtained.
By default, “max count” is selected. The maximum window is targeted over the unit selected in the “Data granularity” section. For options such as seasonal or weekly, “Stride length” can be configured by selecting “Stride length”, and if you want to determine the strategy by adding columns by default, you can select “column” .
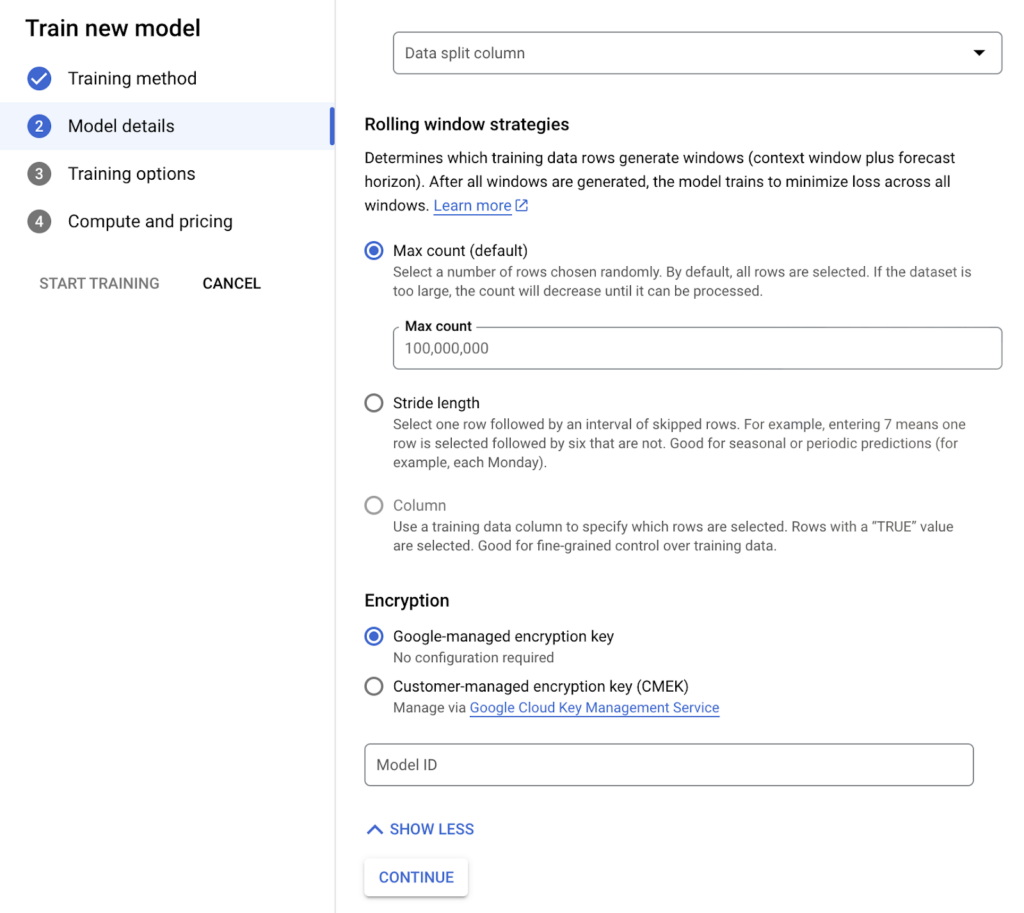
Image 6: Determining Rolling Window Strategy
7. Interpreting Columns for Forecasting
After determining the model details, we continue by entering column-based details in the “Training options” section to edit each column where the data in the model we have is separated and make better predictions.
- “Transformation” is selected by default, if you want to change it you can select “numeric” or “categorical”.
- “Feature type” can be selected as “covariate” or “attribute” .
- Attribute: static attributes that do not change over time. These columns carry information about the product. Features such as the size and color of the product sold are considered as “attributes”.
- Covariate: an exogenous variable that is expected to change over time. If a column is marked as “covariate”, this variable must be provided for each point in the “forecast horizon”. Holidays, scheduled events are treated as “covariate” .
- Finally, the status “available at forecast” is set.
- At “Forecast” time, we mark columns that can be provided to the model as “available” and columns that cannot be provided to the model as “not available”. For example, a column containing weather information is marked as “not available”.
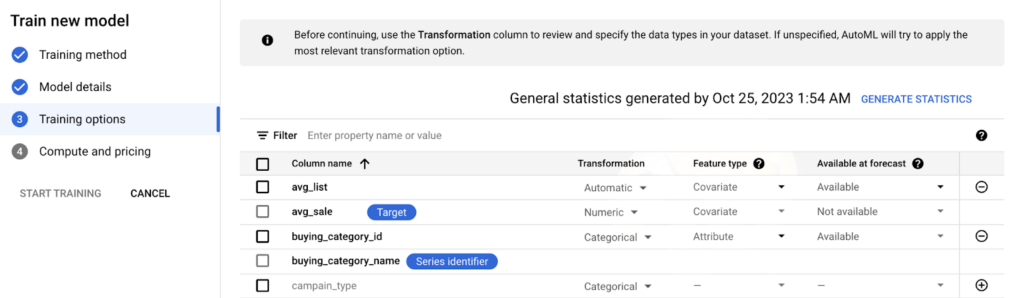
Image 7: Column Adjustment for Forecasting
- Column Prioritization and Optimization Objective Selection
After the columns are interpreted for the model, we can use the “weight column” feature to characterize which rows are more important for us. In the default settings, each column is weighted equally by the model, but if there are rows that we want to weigh more in the model, we can create a “weight” column for these rows and increase the impact of these rows on the model.
Once the important columns have been identified, the optimization objective for our model is selected:
- RMSE: Root-Mean-Squared Error. It better captures more extreme cases and is less biased in forecasting. Selected by default.
- MAE: It minimizes the Mean-Absolute Error. More extreme cases have less impact on the model and are treated as outliers for the model.
- RMSLE: Minimizes Root-Mean-Squared Log Error. It penalizes the error according to the size of the error relative to the absolute value. Useful when both predicted and actual values are large.
- RMSPE: Minimizes the Root-Mean-Squared Percentage Error. It is similar to RMSE. Predicts a wider range of values more accurately.
- WAPE: Used to minimize the combination of Weighted Absolute Percentage Error (WAPE) and Mean-Absolute Error. Useful when actual values are low.
- Quantile Loss: Used to measure uncertainty in forecasts. It measures the probability of a forecast being within a certain range.
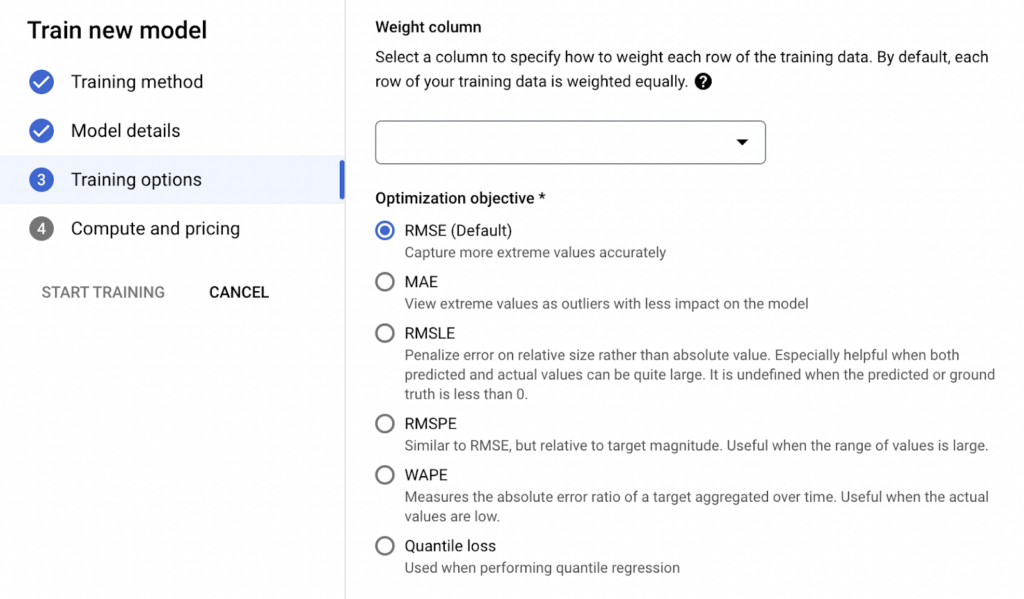
Image 8: Weight Column and Optimization Objective Selection
- Hierarchical Forecasting Settings
Time series are often structured in a nested hierarchy. For example, the entire inventory of products sold by a retailer can be divided into product categories. Categories can also be broken down into individual products. When forecasting future sales, forecasts for the products of a category should be added to forecasts for the category itself, raising the hierarchy. Similarly, the time dimension of a single time series can also exhibit a hierarchy. For example, forecasted sales at the day level for a single product should be added to the forecast weekly sales of the product.
Hierarchical forecasting in Vertex AI takes into account the hierarchical structure of the time series by including additional loss terms for aggregated forecasts. For example, if the hierarchical group is “category”, the forecasts at the “category” level are the sum of forecasts for all “products” in the category. If the objective of the model is the mean absolute error (MAE), the loss will include the MAE for forecasts at both the “product” and “category” levels. This helps to improve the consistency of forecasts at different levels of the hierarchy and in some cases can even improve metrics at the lowest level.
When hierarchical estimation is selected, we are presented with three options:
- No Grouping : hierarchical forecasting without any grouping.
- Group by columns: Hierarchical prediction is made over the selected columns.
- Group All : Hierarchical forecasting is performed by considering all Time Series as a single group.
When we select Group by columns or group all options, the following configurations are opened:
- Group_columns: Column names that define the grouping for the hierarchy level in your Training input table. The column or columns must be “time_series_attribute_columns”. If the group column is not set, all time series are treated as part of the same group and aggregated over all time series.
- Group_total_weight: The weight of the group is the total loss based on individual loss. If set to 0.0 or not set at all, it is disabled and not added to the model.
- Temporal_total_weight: The weight of time against individual loss based on aggregated loss. If set to 0.0 or not set at all, it is disabled and not added to the model.
- Group_temporal_total_weight: Weight of total loss (group x time) based on individual loss. If set to 0.0 or not set at all, it is disabled and not added to the model. If the Group column is not set, all time series are treated as part of the same group and summed over all time series.
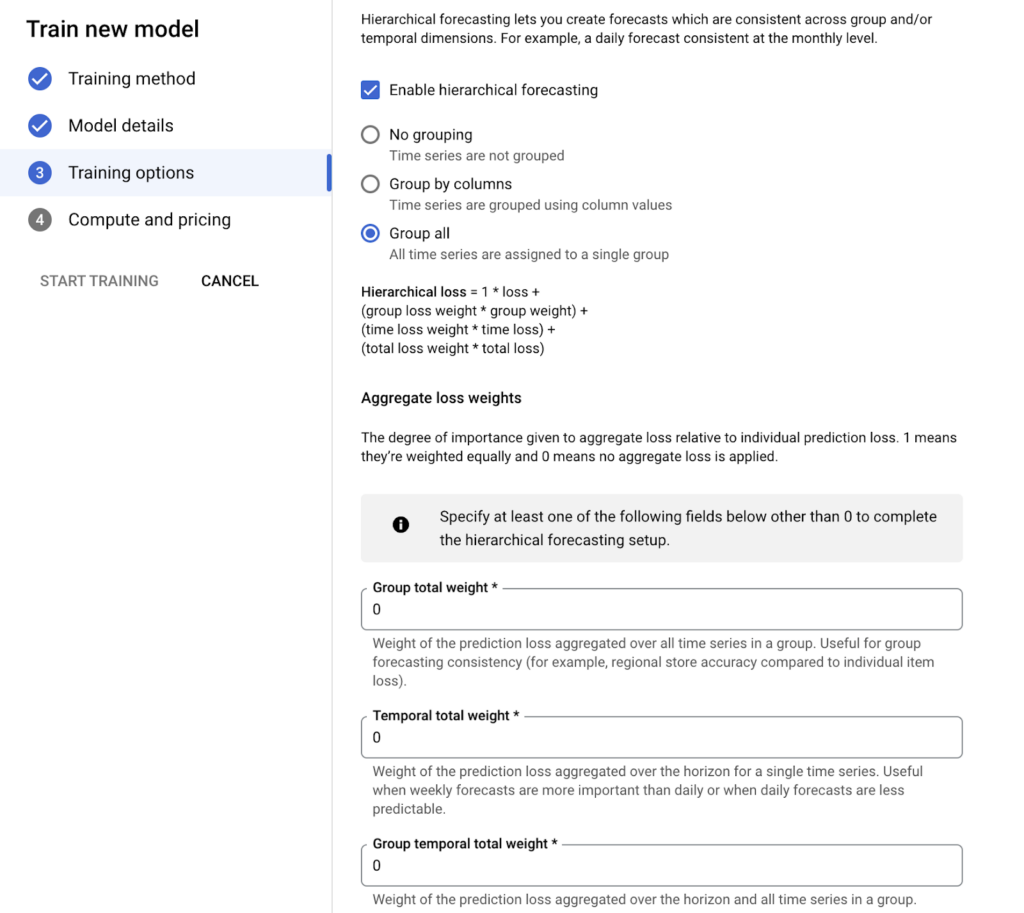
Image 9: Hierarchical Forecasting Settings
10. Running the Model and Budget Setting
After all configurations are completed, budget adjustment is made on the basis of hours of operation. 1 to 3 hours for 100,000 rows, 3 to 6 hours for up to 1,000,000 rows, 12 hours for up to 10,000,000 rows and then as the number of rows increases, the training time and fee can be adjusted by doubling the budget every 10 floors.
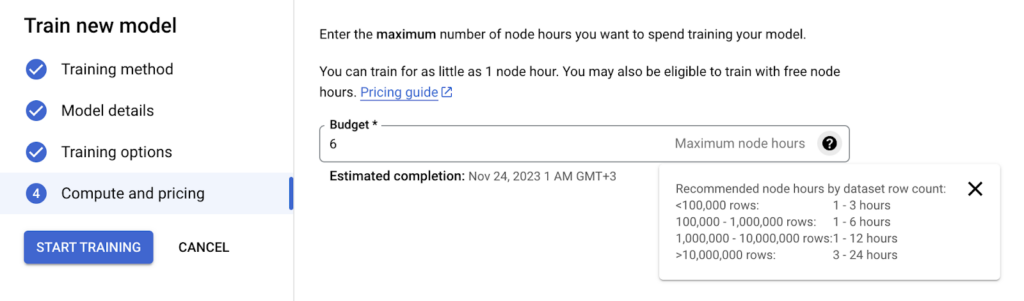
Image 10: Budget Setting
Conclusion and Recommendations
After following the steps, you now have an AI model that you can easily use in your business. Here are a few suggestions to further improve your model in the future:
- For the first training iteration, set the contex window and forecast horizon to the same value and set your training budget to at least 6 hours.
- Retrain the model with the same training budget, but double the size of the contex window to 2 times the forecast horizon.
- If the evaluation metrics for the second model show a significant improvement, retrain the model by increasing the context window to 5 times the size of the forecast horizon. Consider a proportional increase in the training budget (if you trained 10 hours in the first step, increase the training budget to 50 hours).
- Keep increasing the context window until you no longer see the improved evaluation metrics or you are satisfied with the results. Once you find the context window that produces the results you want, you can go back to the lowest value.
To summarize what has been done, even if we do not have enough hardware for our existing businesses and processes, we can easily incorporate artificial intelligence solutions into our processes using Vertex AI AutoML. In this way, automated processes that are much more optimized and successful can be achieved. We hope that this article, written as a guide, will help you to include artificial intelligence in your processes by following the steps.


